Manipulating States and Operators
Introduction
In the previous guide section Basic Operations on Quantum Objects, we saw how to create states and operators, using the functions built into QuTiP. In this portion of the guide, we will look at performing basic operations with states and operators. For more detailed demonstrations on how to use and manipulate these objects, see the examples on the tutorials web page.
State Vectors (kets or bras)
Here we begin by creating a Fock basis vacuum state vector \(\left|0\right>\) with in a Hilbert space with 5 number states, from 0 to 4:
vac = basis(5, 0)
print(vac)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[1.]
[0.]
[0.]
[0.]
[0.]]
and then create a lowering operator \(\left(\hat{a}\right)\) corresponding to 5 number states using the destroy function:
a = destroy(5)
print(a)
Output:
Quantum object: dims = [[5], [5]], shape = (5, 5), type = oper, isherm = False
Qobj data =
[[0. 1. 0. 0. 0. ]
[0. 0. 1.41421356 0. 0. ]
[0. 0. 0. 1.73205081 0. ]
[0. 0. 0. 0. 2. ]
[0. 0. 0. 0. 0. ]]
Now lets apply the destruction operator to our vacuum state vac,
print(a * vac)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0.]
[0.]
[0.]
[0.]
[0.]]
We see that, as expected, the vacuum is transformed to the zero vector. A more interesting example comes from using the adjoint of the lowering operator, the raising operator \(\hat{a}^\dagger\):
print(a.dag() * vac)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0.]
[1.]
[0.]
[0.]
[0.]]
The raising operator has in indeed raised the state vec from the vacuum to the \(\left| 1\right>\) state.
Instead of using the dagger Qobj.dag() method to raise the state, we could have also used the built in create function to make a raising operator:
c = create(5)
print(c * vac)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0.]
[1.]
[0.]
[0.]
[0.]]
which does the same thing. We can raise the vacuum state more than once by successively apply the raising operator:
print(c * c * vac)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0. ]
[0. ]
[1.41421356]
[0. ]
[0. ]]
or just taking the square of the raising operator \(\left(\hat{a}^\dagger\right)^{2}\):
print(c ** 2 * vac)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0. ]
[0. ]
[1.41421356]
[0. ]
[0. ]]
Applying the raising operator twice gives the expected \(\sqrt{n + 1}\) dependence. We can use the product of \(c * a\) to also apply the number operator to the state vector vac:
print(c * a * vac)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0.]
[0.]
[0.]
[0.]
[0.]]
or on the \(\left| 1\right>\) state:
print(c * a * (c * vac))
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0.]
[1.]
[0.]
[0.]
[0.]]
or the \(\left| 2\right>\) state:
print(c * a * (c**2 * vac))
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0. ]
[0. ]
[2.82842712]
[0. ]
[0. ]]
Notice how in this last example, application of the number operator does not give the expected value \(n=2\), but rather \(2\sqrt{2}\). This is because this last state is not normalized to unity as \(c\left| n\right> = \sqrt{n+1}\left| n+1\right>\). Therefore, we should normalize our vector first:
print(c * a * (c**2 * vac).unit())
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0.]
[0.]
[2.]
[0.]
[0.]]
Since we are giving a demonstration of using states and operators, we have done a lot more work than we should have.
For example, we do not need to operate on the vacuum state to generate a higher number Fock state.
Instead we can use the basis (or fock) function to directly obtain the required state:
ket = basis(5, 2)
print(ket)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0.]
[0.]
[1.]
[0.]
[0.]]
Notice how it is automatically normalized. We can also use the built in num operator:
n = num(5)
print(n)
Output:
Quantum object: dims = [[5], [5]], shape = (5, 5), type = oper, isherm = True
Qobj data =
[[0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 2. 0. 0.]
[0. 0. 0. 3. 0.]
[0. 0. 0. 0. 4.]]
Therefore, instead of c * a * (c ** 2 * vac).unit() we have:
print(n * ket)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0.]
[0.]
[2.]
[0.]
[0.]]
We can also create superpositions of states:
ket = (basis(5, 0) + basis(5, 1)).unit()
print(ket)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0.70710678]
[0.70710678]
[0. ]
[0. ]
[0. ]]
where we have used the Qobj.unit method to again normalize the state. Operating with the number function again:
print(n * ket)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[0. ]
[0.70710678]
[0. ]
[0. ]
[0. ]]
We can also create coherent states and squeezed states by applying the displace and squeeze functions to the vacuum state:
vac = basis(5, 0)
d = displace(5, 1j)
s = squeeze(5, np.complex(0.25, 0.25))
print(d * vac)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[ 0.60655682+0.j ]
[ 0. +0.60628133j]
[-0.4303874 +0.j ]
[ 0. -0.24104351j]
[ 0.14552147+0.j ]]
print(d * s * vac)
Output:
Quantum object: dims = [[5], [1]], shape = (5, 1), type = ket
Qobj data =
[[ 0.65893786+0.08139381j]
[ 0.10779462+0.51579735j]
[-0.37567217-0.01326853j]
[-0.02688063-0.23828775j]
[ 0.26352814+0.11512178j]]
Of course, displacing the vacuum gives a coherent state, which can also be generated using the built in coherent function.
Density matrices
One of the main purpose of QuTiP is to explore the dynamics of open quantum systems, where the most general state of a system is no longer a state vector, but rather a density matrix. Since operations on density matrices operate identically to those of vectors, we will just briefly highlight creating and using these structures.
The simplest density matrix is created by forming the outer-product \(\left|\psi\right>\left<\psi\right|\) of a ket vector:
ket = basis(5, 2)
print(ket * ket.dag())
Output:
Quantum object: dims = [[5], [5]], shape = (5, 5), type = oper, isherm = True
Qobj data =
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
A similar task can also be accomplished via the fock_dm or ket2dm functions:
print(fock_dm(5, 2))
Output:
Quantum object: dims = [[5], [5]], shape = (5, 5), type = oper, isherm = True
Qobj data =
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
print(ket2dm(ket))
Output:
Quantum object: dims = [[5], [5]], shape = (5, 5), type = oper, isherm = True
Qobj data =
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
If we want to create a density matrix with equal classical probability of being found in the \(\left|2\right>\) or \(\left|4\right>\) number states we can do the following:
print(0.5 * ket2dm(basis(5, 4)) + 0.5 * ket2dm(basis(5, 2)))
Output:
Quantum object: dims = [[5], [5]], shape = (5, 5), type = oper, isherm = True
Qobj data =
[[0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. ]
[0. 0. 0.5 0. 0. ]
[0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0.5]]
or use 0.5 * fock_dm(5, 2) + 0.5 * fock_dm(5, 4).
There are also several other built-in functions for creating predefined density matrices, for example coherent_dm and thermal_dm which create coherent state and thermal state density matrices, respectively.
print(coherent_dm(5, 1.25))
Output:
Quantum object: dims = [[5], [5]], shape = (5, 5), type = oper, isherm = True
Qobj data =
[[0.20980701 0.26141096 0.23509686 0.15572585 0.13390765]
[0.26141096 0.32570738 0.29292109 0.19402805 0.16684347]
[0.23509686 0.29292109 0.26343512 0.17449684 0.1500487 ]
[0.15572585 0.19402805 0.17449684 0.11558499 0.09939079]
[0.13390765 0.16684347 0.1500487 0.09939079 0.0854655 ]]
print(thermal_dm(5, 1.25))
Output:
Quantum object: dims = [[5], [5]], shape = (5, 5), type = oper, isherm = True
Qobj data =
[[0.46927974 0. 0. 0. 0. ]
[0. 0.26071096 0. 0. 0. ]
[0. 0. 0.14483942 0. 0. ]
[0. 0. 0. 0.08046635 0. ]
[0. 0. 0. 0. 0.04470353]]
QuTiP also provides a set of distance metrics for determining how close two density matrix distributions are to each other.
Included are the trace distance tracedist, fidelity fidelity, Hilbert-Schmidt distance hilbert_dist, Bures distance bures_dist, Bures angle bures_angle, and quantum Hellinger distance hellinger_dist.
x = coherent_dm(5, 1.25)
y = coherent_dm(5, np.complex(0, 1.25)) # <-- note the 'j'
z = thermal_dm(5, 0.125)
np.testing.assert_almost_equal(fidelity(x, x), 1)
np.testing.assert_almost_equal(hellinger_dist(x, y), 1.3819080728932833)
We also know that for two pure states, the trace distance (T) and the fidelity (F) are related by \(T = \sqrt{1 - F^{2}}\), while the quantum Hellinger distance (QHE) between two pure states \(\left|\psi\right>\) and \(\left|\phi\right>\) is given by \(QHE = \sqrt{2 - 2\left|\left<\psi | \phi\right>\right|^2}\).
np.testing.assert_almost_equal(tracedist(y, x), np.sqrt(1 - fidelity(y, x) ** 2))
For a pure state and a mixed state, \(1 - F^{2} \le T\) which can also be verified:
assert 1 - fidelity(x, z) ** 2 < tracedist(x, z)
Qubit (two-level) systems
Having spent a fair amount of time on basis states that represent harmonic oscillator states, we now move on to qubit, or two-level quantum systems (for example a spin-1/2). To create a state vector corresponding to a qubit system, we use the same basis, or fock, function with only two levels:
spin = basis(2, 0)
Now at this point one may ask how this state is different than that of a harmonic oscillator in the vacuum state truncated to two energy levels?
vac = basis(2, 0)
At this stage, there is no difference. This should not be surprising as we called the exact same function twice. The difference between the two comes from the action of the spin operators sigmax, sigmay, sigmaz, sigmap, and sigmam on these two-level states. For example, if vac corresponds to the vacuum state of a harmonic oscillator, then, as we have already seen, we can use the raising operator to get the \(\left|1\right>\) state:
print(vac)
Output:
Quantum object: dims = [[2], [1]], shape = (2, 1), type = ket
Qobj data =
[[1.]
[0.]]
c = create(2)
print(c * vac)
Output:
Quantum object: dims = [[2], [1]], shape = (2, 1), type = ket
Qobj data =
[[0.]
[1.]]
For a spin system, the operator analogous to the raising operator is the sigma-plus operator sigmap. Operating on the spin state gives:
print(spin)
Output:
Quantum object: dims = [[2], [1]], shape = (2, 1), type = ket
Qobj data =
[[1.]
[0.]]
print(sigmap() * spin)
Output:
Quantum object: dims = [[2], [1]], shape = (2, 1), type = ket
Qobj data =
[[0.]
[0.]]
Now we see the difference! The sigmap operator acting on the spin state returns the zero vector. Why is this? To see what happened, let us use the sigmaz operator:
print(sigmaz())
Output:
Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = True
Qobj data =
[[ 1. 0.]
[ 0. -1.]]
print(sigmaz() * spin)
Output:
Quantum object: dims = [[2], [1]], shape = (2, 1), type = ket
Qobj data =
[[1.]
[0.]]
spin2 = basis(2, 1)
print(spin2)
Output:
Quantum object: dims = [[2], [1]], shape = (2, 1), type = ket
Qobj data =
[[0.]
[1.]]
print(sigmaz() * spin2)
Output:
Quantum object: dims = [[2], [1]], shape = (2, 1), type = ket
Qobj data =
[[ 0.]
[-1.]]
The answer is now apparent. Since the QuTiP sigmaz function uses the standard z-basis representation of the sigma-z spin operator, the spin state corresponds to the \(\left|\uparrow\right>\) state of a two-level spin system while spin2 gives the \(\left|\downarrow\right>\) state. Therefore, in our previous example sigmap() * spin, we raised the qubit state out of the truncated two-level Hilbert space resulting in the zero state.
While at first glance this convention might seem somewhat odd, it is in fact quite handy. For one, the spin operators remain in the conventional form. Second, when the spin system is in the \(\left|\uparrow\right>\) state:
print(sigmaz() * spin)
Output:
Quantum object: dims = [[2], [1]], shape = (2, 1), type = ket
Qobj data =
[[1.]
[0.]]
the non-zero component is the zeroth-element of the underlying matrix (remember that python uses c-indexing, and matrices start with the zeroth element). The \(\left|\downarrow\right>\) state therefore has a non-zero entry in the first index position. This corresponds nicely with the quantum information definitions of qubit states, where the excited \(\left|\uparrow\right>\) state is label as \(\left|0\right>\), and the \(\left|\downarrow\right>\) state by \(\left|1\right>\).
If one wants to create spin operators for higher spin systems, then the jmat function comes in handy.
Gates
The pre-defined gates are shown in the table below:
Gate function |
Description |
|---|---|
Rotation around x axis |
|
Rotation around y axis |
|
Rotation around z axis |
|
Square root of not gate |
|
Square root of not gate |
|
Hardmard gate |
|
Phase shift gate |
|
A qubit rotation under a Rabi pulse |
|
Controlled y gate |
|
Controlled z gate |
|
Single-qubit rotation |
|
Square root of s gate |
|
Controlled s gate |
|
Controlled t gate |
|
Controlled phase gate |
|
Controlled not gate |
|
Same as cphase |
|
Berkeley gate |
|
Swapalpha gate |
|
Swap the states of two qubits |
|
Swap gate with additional phase for 01 and 10 states |
|
Square root of the swap gate |
|
Square root of the iswap gate |
|
Fredkin gate |
|
Molmer Sorensen gate |
|
Toffoli gate |
|
Hadamard gate |
|
Generates the Clifford group on a single qubit |
|
Global phase gate |
To load this qutip module, first you have to import gates:
from qutip import gates
For example to use the Hadamard Gate:
H = gates.hadamard_transform()
print(H)
Output:
Quantum object: dims=[[2], [2]], shape=(2, 2), type='oper', dtype=Dense, isherm=True
Qobj data =
[[ 0.70710678 0.70710678]
[0.70710678 -0.70710678]]
Expectation values
Some of the most important information about quantum systems comes from calculating the expectation value of operators, both Hermitian and non-Hermitian, as the state or density matrix of the system varies in time. Therefore, in this section we demonstrate the use of the expect function. To begin:
vac = basis(5, 0)
one = basis(5, 1)
c = create(5)
N = num(5)
np.testing.assert_almost_equal(expect(N, vac), 0)
np.testing.assert_almost_equal(expect(N, one), 1)
coh = coherent_dm(5, 1.0j)
np.testing.assert_almost_equal(expect(N, coh), 0.9970555745806597)
cat = (basis(5, 4) + 1.0j * basis(5, 3)).unit()
np.testing.assert_almost_equal(expect(c, cat), 0.9999999999999998j)
The expect function also accepts lists or arrays of state vectors or density matrices for the second input:
states = [(c**k * vac).unit() for k in range(5)] # must normalize
print(expect(N, states))
Output:
[0. 1. 2. 3. 4.]
cat_list = [(basis(5, 4) + x * basis(5, 3)).unit() for x in [0, 1.0j, -1.0, -1.0j]]
print(expect(c, cat_list))
Output:
[ 0.+0.j 0.+1.j -1.+0.j 0.-1.j]
Notice how in this last example, all of the return values are complex numbers. This is because the expect function looks to see whether the operator is Hermitian or not. If the operator is Hermitian, then the output will always be real. In the case of non-Hermitian operators, the return values may be complex. Therefore, the expect function will return an array of complex values for non-Hermitian operators when the input is a list/array of states or density matrices.
Of course, the expect function works for spin states and operators:
up = basis(2, 0)
down = basis(2, 1)
np.testing.assert_almost_equal(expect(sigmaz(), up), 1)
np.testing.assert_almost_equal(expect(sigmaz(), down), -1)
as well as the composite objects discussed in the next section Using Tensor Products and Partial Traces:
spin1 = basis(2, 0)
spin2 = basis(2, 1)
two_spins = tensor(spin1, spin2)
sz1 = tensor(sigmaz(), qeye(2))
sz2 = tensor(qeye(2), sigmaz())
np.testing.assert_almost_equal(expect(sz1, two_spins), 1)
np.testing.assert_almost_equal(expect(sz2, two_spins), -1)
Block Matrices (Direct Sums)
QuTiP supports building vectors and matrices out of blocks that contain smaller matrices, vectors or numbers. Mathematically, this operation is called a “direct sum” or “direct product”. For example, given a vector \(|\psi\rangle\) in the 2-dimensional Hilbert space \(\mathcal H_2\), and another vector \(|\phi\rangle\) in the 3-dimensional, we can form a vector \(|\psi\rangle \oplus |\phi\rangle\) in the sum space \(\mathcal H_2 \oplus \mathcal H_3\), which is a 5-dimensional space. This vector is nothing but the two original vectors stacked on top of each other.
psi = Qobj([[1], [1]])
phi = Qobj([[2], [2], [2]])
psi_plus_phi = direct_sum([psi, phi])
print(psi_plus_phi)
Output:
Quantum object: dims=[([2], [3]), [1]], shape=(5, 1), type='ket', dtype=CSR
Qobj data =
[[1.]
[1.]
[2.]
[2.]
[2.]]
Note that the dimensions of this quantum object now read [([2], [3]), [1]].
The parentheses denote a direct sum.
The following is a more complex example:
block_operator = direct_sum(
[[ sigmax(), None ],
[ basis(2, 0).dag(), -1 ]]
)
print(block_operator)
Output:
Quantum object: dims=[([2], [1]), ([2], [1])], shape=(3, 3), type='oper', dtype=CSR, isherm=False
Qobj data =
[[ 0. 1. 0.]
[ 1. 0. 0.]
[ 1. 0. -1.]]
The direct_sum function also supports time-dependent operators as well as superoperators and vectorized operators.
It can be useful to model coupled differential equations.
The functions direct_component can be used to extract blocks from a direct sum, and set_direct_component overwrites a block in a direct sum.
Superoperators and Vectorized Operators
In addition to state vectors and density operators, QuTiP allows for representing maps that act linearly on density operators using the Kraus, Liouville supermatrix and Choi matrix formalisms. This support is based on the correspondence between linear operators acting on a Hilbert space, and vectors in two copies of that Hilbert space, \(\mathrm{vec} : \mathcal{L}(\mathcal{H}) \to \mathcal{H} \otimes \mathcal{H}\) [Hav03], [Wat13].
This isomorphism is implemented in QuTiP by the
operator_to_vector and
vector_to_operator functions:
psi = basis(2, 0)
rho = ket2dm(psi)
print(rho)
Output:
Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = True
Qobj data =
[[1. 0.]
[0. 0.]]
vec_rho = operator_to_vector(rho)
print(vec_rho)
Output:
Quantum object: dims = [[[2], [2]], [1]], shape = (4, 1), type = operator-ket
Qobj data =
[[1.]
[0.]
[0.]
[0.]]
rho2 = vector_to_operator(vec_rho)
np.testing.assert_almost_equal((rho - rho2).norm(), 0)
The Qobj.type attribute indicates whether a quantum object is
a vector corresponding to an operator (operator-ket), or its Hermitian
conjugate (operator-bra).
Note that QuTiP uses the column-stacking convention for the isomorphism between \(\mathcal{L}(\mathcal{H})\) and \(\mathcal{H} \otimes \mathcal{H}\):
A = Qobj(np.arange(4).reshape((2, 2)))
print(A)
Output:
Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = False
Qobj data =
[[0. 1.]
[2. 3.]]
print(operator_to_vector(A))
Output:
Quantum object: dims = [[[2], [2]], [1]], shape = (4, 1), type = operator-ket
Qobj data =
[[0.]
[2.]
[1.]
[3.]]
Since \(\mathcal{H} \otimes \mathcal{H}\) is a vector space, linear maps
on this space can be represented as matrices, often called superoperators.
Using the Qobj, the spre and spost functions, supermatrices
corresponding to left- and right-multiplication respectively can be quickly
constructed.
X = sigmax()
S = spre(X) * spost(X.dag()) # Represents conjugation by X.
Note that this is done automatically by the to_super function when given
type='oper' input.
S2 = to_super(X)
np.testing.assert_almost_equal((S - S2).norm(), 0)
Quantum objects representing superoperators are denoted by type='super':
print(S)
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = True
Qobj data =
[[0. 0. 0. 1.]
[0. 0. 1. 0.]
[0. 1. 0. 0.]
[1. 0. 0. 0.]]
Information about superoperators, such as whether they represent completely
positive maps, is exposed through the Qobj.iscp, Qobj.istp
and Qobj.iscptp attributes:
print(S.iscp, S.istp, S.iscptp)
Output:
True True True
In addition, dynamical generators on this extended space, often called
Liouvillian superoperators, can be created using the liouvillian function. Each of these takes a Hamiltonian along with
a list of collapse operators, and returns a type="super" object that can
be exponentiated to find the superoperator for that evolution.
H = 10 * sigmaz()
c1 = destroy(2)
L = liouvillian(H, [c1])
print(L)
S = (12 * L).expm()
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = False
Qobj data =
[[ 0. +0.j 0. +0.j 0. +0.j 1. +0.j]
[ 0. +0.j -0.5+20.j 0. +0.j 0. +0.j]
[ 0. +0.j 0. +0.j -0.5-20.j 0. +0.j]
[ 0. +0.j 0. +0.j 0. +0.j -1. +0.j]]
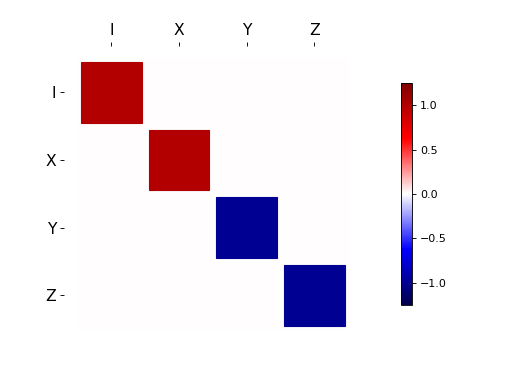
For qubits, a particularly useful way to visualize superoperators is to plot them in the Pauli basis, such that \(S_{\mu,\nu} = \langle\!\langle \sigma_{\mu} | S[\sigma_{\nu}] \rangle\!\rangle\). Because the Pauli basis is Hermitian, \(S_{\mu,\nu}\) is a real number for all Hermitian-preserving superoperators \(S\), allowing us to plot the elements of \(S\) as a Hinton diagram. In such diagrams, positive elements are indicated by white squares, and negative elements by black squares. The size of each element is indicated by the size of the corresponding square. For instance, let \(S[\rho] = \sigma_x \rho \sigma_x^{\dagger}\). Then \(S[\sigma_{\mu}] = \sigma_{\mu} \cdot \begin{cases} +1 & \mu = 0, x \\ -1 & \mu = y, z \end{cases}\). We can quickly see this by noting that the \(Y\) and \(Z\) elements of the Hinton diagram for \(S\) are negative:
from qutip import *
settings.colorblind_safe = True
import matplotlib.pyplot as plt
plt.rcParams['savefig.transparent'] = True
X = sigmax()
S = spre(X) * spost(X.dag())
hinton(S)
Choi, Kraus, Stinespring and \(\chi\) Representations
In addition to the superoperator representation of quantum maps, QuTiP supports several other useful representations. First, the Choi matrix \(J(\Lambda)\) of a quantum map \(\Lambda\) is useful for working with ancilla-assisted process tomography (AAPT), and for reasoning about properties of a map or channel. Up to normalization, the Choi matrix is defined by acting \(\Lambda\) on half of an entangled pair. In the column-stacking convention,
In QuTiP, \(J(\Lambda)\) can be found by calling the to_choi
function on a type="super" Qobj.
X = sigmax()
S = sprepost(X, X)
J = to_choi(S)
print(J)
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = True, superrep = choi
Qobj data =
[[0. 0. 0. 0.]
[0. 1. 1. 0.]
[0. 1. 1. 0.]
[0. 0. 0. 0.]]
print(to_choi(spre(qeye(2))))
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = True, superrep = choi
Qobj data =
[[1. 0. 0. 1.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[1. 0. 0. 1.]]
If a Qobj instance is already in the Choi Qobj.superrep, then calling to_choi
does nothing:
print(to_choi(J))
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = True, superrep = choi
Qobj data =
[[0. 0. 0. 0.]
[0. 1. 1. 0.]
[0. 1. 1. 0.]
[0. 0. 0. 0.]]
To get back to the superoperator representation, simply use the to_super function.
As with to_choi, to_super is idempotent:
print(to_super(J) - S)
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = True
Qobj data =
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
print(to_super(S))
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = True
Qobj data =
[[0. 0. 0. 1.]
[0. 0. 1. 0.]
[0. 1. 0. 0.]
[1. 0. 0. 0.]]
We can quickly obtain another useful representation from the Choi matrix by taking its eigendecomposition. In particular, let \(\{A_i\}\) be a set of operators such that \(J(\Lambda) = \sum_i |A_i\rangle\!\rangle \langle\!\langle A_i|\). We can write \(J(\Lambda)\) in this way for any hermicity-preserving map; that is, for any map \(\Lambda\) such that \(J(\Lambda) = J^\dagger(\Lambda)\). These operators then form the Kraus representation of \(\Lambda\). In particular, for any input \(\rho\),
Notice using the column-stacking identity that \((C^\mathrm{T} \otimes A) |B\rangle\!\rangle = |ABC\rangle\!\rangle\), we have that
The Kraus representation of a hermicity-preserving map can be found in QuTiP
using the to_kraus function.
del sum # np.sum overwrote sum and caused a bug.
I, X, Y, Z = qeye(2), sigmax(), sigmay(), sigmaz()
S = sum([sprepost(P, P) for P in (I, X, Y, Z)]) / 4
print(S)
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = True
Qobj data =
[[0.5 0. 0. 0.5]
[0. 0. 0. 0. ]
[0. 0. 0. 0. ]
[0.5 0. 0. 0.5]]
J = to_choi(S)
print(J)
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = True, superrep = choi
Qobj data =
[[0.5 0. 0. 0. ]
[0. 0.5 0. 0. ]
[0. 0. 0.5 0. ]
[0. 0. 0. 0.5]]
print(J.eigenstates()[1])
Output:
[Quantum object: dims = [[[2], [2]], [1, 1]], shape = (4, 1), type = operator-ket
Qobj data =
[[1.]
[0.]
[0.]
[0.]]
Quantum object: dims = [[[2], [2]], [1, 1]], shape = (4, 1), type = operator-ket
Qobj data =
[[0.]
[1.]
[0.]
[0.]]
Quantum object: dims = [[[2], [2]], [1, 1]], shape = (4, 1), type = operator-ket
Qobj data =
[[0.]
[0.]
[1.]
[0.]]
Quantum object: dims = [[[2], [2]], [1, 1]], shape = (4, 1), type = operator-ket
Qobj data =
[[0.]
[0.]
[0.]
[1.]]]
K = to_kraus(S)
print(K)
Output:
[Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = True
Qobj data =
[[0.70710678 0. ]
[0. 0. ]], Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = False
Qobj data =
[[0. 0. ]
[0.70710678 0. ]], Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = False
Qobj data =
[[0. 0.70710678]
[0. 0. ]], Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = True
Qobj data =
[[0. 0. ]
[0. 0.70710678]]]
As with the other representation conversion functions, to_kraus
checks the Qobj.superrep attribute of its input, and chooses an appropriate
conversion method. Thus, in the above example, we can also call to_kraus
on J.
KJ = to_kraus(J)
print(KJ)
Output:
[Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = True
Qobj data =
[[0.70710678 0. ]
[0. 0. ]], Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = False
Qobj data =
[[0. 0. ]
[0.70710678 0. ]], Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = False
Qobj data =
[[0. 0.70710678]
[0. 0. ]], Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = True
Qobj data =
[[0. 0. ]
[0. 0.70710678]]]
for A, AJ in zip(K, KJ):
print(A - AJ)
Output:
Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = True
Qobj data =
[[0. 0.]
[0. 0.]]
Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = True
Qobj data =
[[0. 0.]
[0. 0.]]
Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = True
Qobj data =
[[0. 0.]
[0. 0.]]
Quantum object: dims = [[2], [2]], shape = (2, 2), type = oper, isherm = True
Qobj data =
[[0. 0.]
[0. 0.]]
The Stinespring representation is closely related to the Kraus representation, and consists of a pair of operators \(A\) and \(B\) such that for all operators \(X\) acting on \(\mathcal{H}\),
where the partial trace is over a new index that corresponds to the
index in the Kraus summation. Conversion to Stinespring
is handled by the to_stinespring
function.
a = create(2).dag()
S_ad = sprepost(a * a.dag(), a * a.dag()) + sprepost(a, a.dag())
S = 0.9 * sprepost(I, I) + 0.1 * S_ad
print(S)
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = False
Qobj data =
[[1. 0. 0. 0.1]
[0. 0.9 0. 0. ]
[0. 0. 0.9 0. ]
[0. 0. 0. 0.9]]
A, B = to_stinespring(S)
print(A)
Output:
Quantum object: dims = [[2, 3], [2]], shape = (6, 2), type = oper, isherm = False
Qobj data =
[[-0.98845443 0. ]
[ 0. 0.31622777]
[ 0.15151842 0. ]
[ 0. -0.93506452]
[ 0. 0. ]
[ 0. -0.16016975]]
print(B)
Output:
Quantum object: dims = [[2, 3], [2]], shape = (6, 2), type = oper, isherm = False
Qobj data =
[[-0.98845443 0. ]
[ 0. 0.31622777]
[ 0.15151842 0. ]
[ 0. -0.93506452]
[ 0. 0. ]
[ 0. -0.16016975]]
Notice that a new index has been added, such that \(A\) and \(B\)
have dimensions [[2, 3], [2]], with the length-3 index representing the
fact that the Choi matrix is rank-3 (alternatively, that the map has three
Kraus operators).
to_kraus(S)
print(to_choi(S).eigenenergies())
Output:
[0. 0.04861218 0.1 1.85138782]
Finally, the last superoperator representation supported by QuTiP is the \(\chi\)-matrix representation,
where \(\{B_\alpha\}\) is a basis for the space of matrices acting
on \(\mathcal{H}\). In QuTiP, this basis is taken to be the Pauli
basis \(B_\alpha = \sigma_\alpha / \sqrt{2}\). Conversion to the
\(\chi\) formalism is handled by the to_chi
function.
chi = to_chi(S)
print(chi)
Output:
Quantum object: dims = [[[2], [2]], [[2], [2]]], shape = (4, 4), type = super, isherm = True, superrep = chi
Qobj data =
[[3.7+0.j 0. +0.j 0. +0.j 0.1+0.j ]
[0. +0.j 0.1+0.j 0. +0.1j 0. +0.j ]
[0. +0.j 0. -0.1j 0.1+0.j 0. +0.j ]
[0.1+0.j 0. +0.j 0. +0.j 0.1+0.j ]]
One convenient property of the \(\chi\) matrix is that the average gate fidelity with the identity map can be read off directly from the \(\chi_{00}\) element:
np.testing.assert_almost_equal(average_gate_fidelity(S), 0.9499999999999998)
print(chi[0, 0] / 4)
Output:
(0.925+0j)
Here, the factor of 4 comes from the dimension of the underlying
Hilbert space \(\mathcal{H}\). As with the superoperator
and Choi representations, the \(\chi\) representation is
denoted by the Qobj.superrep, such that to_super,
to_choi, to_kraus,
to_stinespring and to_chi
all convert from the \(\chi\) representation appropriately.
Properties of Quantum Maps
In addition to converting between the different representations of quantum maps,
QuTiP also provides attributes to make it easy to check if a map is completely
positive, trace preserving and/or hermicity preserving. Each of these attributes
uses Qobj.superrep to automatically perform any needed conversions.
In particular, a quantum map is said to be positive (but not necessarily completely positive) if it maps all positive operators to positive operators. For instance, the transpose map \(\Lambda(\rho) = \rho^{\mathrm{T}}\) is a positive map. We run into problems, however, if we tensor \(\Lambda\) with the identity to get a partial transpose map.
rho = ket2dm(bell_state())
rho_out = partial_transpose(rho, [0, 1])
print(rho_out.eigenenergies())
Output:
[-0.5 0.5 0.5 0.5]
Notice that even though we started with a positive map, we got an operator out
with negative eigenvalues. Complete positivity addresses this by requiring that
a map returns positive operators for all positive operators, and does so even
under tensoring with another map. The Choi matrix is very useful here, as it
can be shown that a map is completely positive if and only if its Choi matrix
is positive [Wat13]. QuTiP implements this check with the Qobj.iscp
attribute. As an example, notice that the snippet above already calculates
the Choi matrix of the transpose map by acting it on half of an entangled
pair. We simply need to manually set the dims and superrep attributes to reflect the
structure of the underlying Hilbert space and the chosen representation.
J = rho_out
J.dims = [[[2], [2]], [[2], [2]]]
J.superrep = 'choi'
print(J.iscp)
Output:
False
This confirms that the transpose map is not completely positive. On the other hand,
the transpose map does satisfy a weaker condition, namely that it is hermicity preserving.
That is, \(\Lambda(\rho) = (\Lambda(\rho))^\dagger\) for all \(\rho\) such that
\(\rho = \rho^\dagger\). To see this, we note that \((\rho^{\mathrm{T}})^\dagger
= \rho^*\), the complex conjugate of \(\rho\). By assumption, \(\rho = \rho^\dagger
= (\rho^*)^{\mathrm{T}}\), though, such that \(\Lambda(\rho) = \Lambda(\rho^\dagger) = \rho^*\).
We can confirm this by checking the Qobj.ishp attribute:
print(J.ishp)
Output:
True
Next, we note that the transpose map does preserve the trace of its inputs, such that
\(\operatorname{Tr}(\Lambda[\rho]) = \operatorname{Tr}(\rho)\) for all \(\rho\).
This can be confirmed by the Qobj.istp attribute:
print(J.istp)
Output:
False
Finally, a map is called a quantum channel if it always maps valid states to valid states. Formally, a map is a channel if it is both completely positive and trace preserving. Thus, QuTiP provides a single attribute to quickly check that this is true.
>>> print(J.iscptp)
False
>>> print(to_super(qeye(2)).iscptp)
True